date()
sapply(c("pipeR", "dplyr", "tidyr", "purrr", "ggplot2", "readr"), require, character.only= TRUE)
11.1 例題: 一次元空間上の個体数分布¶
- 調査区画: 50個
- とある植物の区画ごとの個体数を数えた
- 局所密度 に類似性がある
load("data/chap11/Y.RData")
ls.str()
options(repr.plot.width = 4,repr.plot.height = 3)
# Fig. 11.2
data_frame(j = seq_along(Y), y = Y) %>>%
ggplot(aes(x = j, y = y)) +
geom_point(shape = 21)+
theme_bw() +
theme(panel.grid = element_blank()) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 25))

11.2 階層ベイズモデルに空間構造をくみこむ¶
個体数 $y_j$ がすべての区画で共通の平均値 $\lambda$ のポアソン分布に従うとする.
$$ p(y_j \mid \lambda) = \frac{\lambda^{y_j}\exp(-\lambda)}{y_j!} $$標本平均は,
mean(Y)
10.9 ぐらいなので,分散も同じぐらいになるはずだが,標本分散は,
var(Y)
27.4 ぐらいなので,過分散が生じている.
図 11.2 を見ると,個体数 $y_j$ は位置によって変化しているように見える.
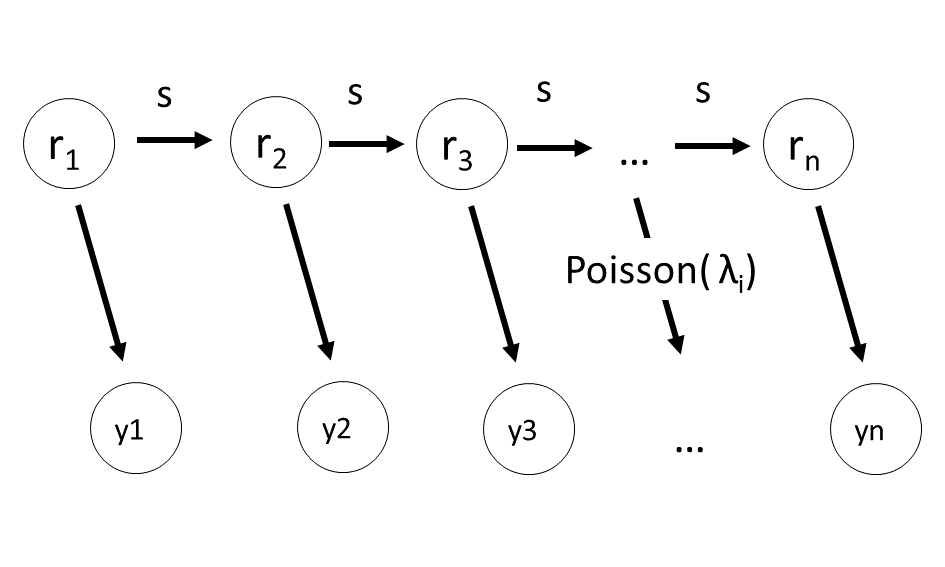
区画ごとに異なる $\lambda_j$ をもつとする. 平均個体数 $\lambda_j$ を線形予測子と対数リンク関数を用いて,以下のようにあらわす.
$$\log \lambda_j =\beta + r_j$$ここで,
- $\beta$ は切片で大域的なパラメータ => 無情報事前分布
- $r_j$ は場所差で局所的なパラメータ => 階層事前分布
11.2.1 空間構造のない階層事前分布¶
場所差 $r_j$ の階層事前分布
- 10章のようにすると,$r_j$ はどれも独立になる
- 平均0,標準偏差s の正規分布
*
readLines("chap11-model5.jags") %>>% cat(sep = "\n")
data.list <- list(
N.site = length(Y),
Y = Y
)
library(rjags)
m <- jags.model(
file = "chap11-model5.jags",
data = data.list,
n.chain = 3,
n.adapt = 100
)
post.jags <- coda.samples(m, variable.names = c("r", "s", "beta"), n.iter = 10000, thin = 10)
# saveRDS(post.jags, file = "chap11-post-jags.rds")
post.jags <- readRDS("chap11-post-jags.rds")
options(repr.plot.width = 4, repr.plot.height = 3)
gp.glmm <- (function(){
beta <- summary(post.jags[, "beta"])$statistics[["Mean"]]
Y.mean <- exp(beta + summary(post.jags[, grep("r", varnames(post.jags))])$statistics[, "Mean"])
Y.qnt <- exp(beta + summary(post.jags[, grep("r", varnames(post.jags))])$quantiles[, c("2.5%", "97.5%")])
data_frame(site = seq_along(Y),
Y = Y,
Y.mean = Y.mean,
Y.975 = Y.qnt[, 2],
Y.025 = Y.qnt[, 1]) %>>%
ggplot() +
geom_point(aes(x = site, y = Y)) +
geom_line(aes(x = site, y = Y.mean)) +
geom_ribbon(aes(x = site, ymin = Y.025, ymax = Y.975), alpha = 0.3) +
theme_bw() +
theme(
panel.grid = element_blank()
) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 30))
})()
gp.glmm

11.2.2 空間構造のある階層事前分布¶
場所差$r_j$に制約を設ける
- 場所差は「近傍」区画の場所差にしか影響されない
- 区画$j$の近傍の個数 $n_j$ は有限個であり,どの区画が近傍であるかはあらかじめ設定する
- 近傍の直接の影響はどれも等しく,$1 / n_j$
簡単のために,近傍数は2とする
- 両隣の影響しか受けない
- 両端については近傍数1
$r_j$ の事前分布を以下のように設定する
$$ p(r_j \mid \mu_j, s) = \sqrt{\frac{n_j}{2 \pi s^2}} \exp \left\{ -\frac{(r_j - \mu_j)^2}{2s^2 / n_j} \right\} $$ここで,平均 $\mu_j$ は近傍の平均値に等しいとする
$$ \mu_j = \frac{r_{j-1} + r_{j+1}}{2} $$- 両端では,$\mu_1 = r_2$,$\mu_{50} = r_49$
- 標準偏差は $s / \sqrt{n_j}$
- $s$ はどこでも等しい
条件つき自己回帰(Conditional Auto Regressive, CAR)モデル
のなかでも
intristic Gaussian CAR モデルという
場所差 $\{ r_j \} = \{ r_1, r_2, \ldots, r_{50}\}$ 全体の事前分布である同時分布は,以下のように書ける
- $j \sim j^\prime$ は$j$と $j^\prime$ が近傍であるようなすべての $\{j, j^\prime\}$ の組み合わせ
この同時分布において,$r_j$を除くすべての$\{ r_* \}$ を定数とおくと,条件つき事前分布 $p(r_j \mid \mu_j, s)$ が得られる(Full Conditional 形式).
11.3 空間統計モデルをデータにあてはめる¶
事前分布は,
$$ p(\beta, s, \{ r_j \} \mid \boldsymbol{Y}) \propto p(\{ r_j \} \mid s) p(s) p(\beta) \prod\limits_j p(y_j \mid \lambda_j) $$- データ $y_j$ が得られる確率: 平均 $\lambda_j = \exp (\beta + r_j)$ のポアソン分布
- $\beta$の事前分布: 無情報事前分布($p(\beta)$)
- $r_j$ の事前分布: 空間構造を考慮した階層事前分布(同時分布$p(\{ r_j \} \mid s)$)
- 個々の$r_j$ の条件付事前分布: 平均 $\mu_j$,標準偏差 $s/\sqrt{n_j}$の正規分布 $p(r_j \mid \mu_j, s)$
- $s$ の事前分布: 無情報事前分布($p(s)$)
WinBUGS を使う場合¶
car.normal()を使うと,Intristic Gaussian CAR モデルを扱える
readLines("chap11-model.jags", encoding = "UTF-8") %>>% cat(sep = "\n")
JAGS を使う場合¶
car.normal() はないが,Intristic CAR モデル は状態空間モデル の形式で表現することができるので,こちらの形式で考える.
時間・空間を含むベイズモデルは,いくつかの形式で表現できる
(詳しくは
などを参照.以降の説明は 『岩波データサイエンス Vol.1』 より)
岩波データサイエンス Vol.1 では以下の4つが紹介されている.
- 状態空間モデル
- 条件つき分布
- マルコフ場モデル
- Full Conditional
(マルコフ場モデルはスキップ)
今回の
$$ p(r_j \mid r_{-j}) = \sqrt{\frac{n_j}{2 \pi s^2}} \exp \left\{-\frac{n_j}{2s^2}\left[ r_j - \frac{1}{2}(r_{j-1} + r_{j+1}) \right]^2 \right\} $$は,各変数についてそれ以外のすべての変数を固定した条件つき分布であり,(4)Full Conditional な形式である
これは,p.248の注釈9にある通り,有向非巡回グラフ(Directed acyclic graph,DAG)ではないので,JAGS で直接表現できない.
なので,例題を状態空間モデル の形式で表現して,こちらの形式を使ってJAGSで計算する.
一般的なはなし
状態空間モデル¶
ある隠れた状態 $\{ x_i\} = \{x_1, x_2, \ldots, x_i \}$ から データ $\{ y_i\} = \{y_1, y_2, \ldots, y_i \}$ が観測されるとする.
$x_i$ に システム雑音 $\eta_i$ が加わって $x_{i+1}$ に遷移し,$x_i$ から $y_i$ を観測する際には,観測雑音 $\epsilon_i$ が加わるとすると,
$$ \begin{align} x_{i+1} &= x_i + \eta_i \\ y_i &= x_i + \epsilon_i \end{align} $$となる.
条件つき分布¶
(1)の状態空間モデルの形式を,JAGS で書きやすいように, 状態間の移動をあらわす条件つき密度 $p(x_{i+1} \mid x_i )$ と 測定のときの誤差をあらわす条件つき密度 $p(y_i \mid x_i)$ で表現する.
$$ \begin{align} \eta_i &= x_{i+1} - x_i \\ \epsilon_i &= y_i - x_i \end{align} $$なので,
$$ p(x_{i+1} \mid x_i ) = \frac{1}{\sqrt{2 \pi s^2}} \exp \left( -\frac{1}{2 s^2} (x_{i+1} - x_i)^2 \right)$$$$ p(y_i \mid x_i) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp \left( -\frac{1}{2 \sigma^2} (y_{i} - x_i)^2 \right) $$また,初期値 $x_1$ の事前密度 $p(x_1)$を,平均0,分散$r^2$の正規分布とし,$s^2$,$\sigma^2$の事前密度を $p(s^2)$,$p(\sigma^2)$ とすると,ベイズモデルを定義する同時密度は,次のようになる.
$$ p(\{y_i\}, \{x_i\}, s^2, \sigma^2) = p(s^2) p(\sigma^2)p(x_1) \prod\limits^{N}_{i=1}p(y_i \mid x_i) \prod\limits^{N-1}_{i=1}p(x_{i+1} \mid x_i) $$具体的なはなし
今回の例題だと¶
- 観測値 $y$ は平均$\lambda$のポアソン分布に従う
- $\lambda$ の対数が 状態 $r$ になる
- 状態 $r$ は標準偏差 $s$ の正規分布にしたがってランダムウォークする
readLines("chap11-model2.jags", encoding = "UTF-8") %>>% cat(sep = "\n")
data.list2 <- list(
N.site = length(Y),
Y = Y
)
data.list2
m2 <- jags.model(
file = "chap11-model2.jags",
data = data.list2,
n.chain = 3,
n.adapt = 100
)
post.jags2 <- coda.samples(m2, variable.names = c("r", "s"), n.iter = 10000, thin = 10)
# saveRDS(post.jags2, file = "chap11-post-jags2.rds")
post.jags2 <- readRDS(file = "chap11-post-jags2.rds")
summary(post.jags2)
gelman.diag(post.jags2)
varnames(post.jags2)
gp.car <- (function(){
Y.mean <- exp(summary(post.jags2[, grep("r", varnames(post.jags2))])$statistics[, "Mean"])
Y.qnt <- exp(summary(post.jags2[, grep("r", varnames(post.jags2))])$quantiles[, c("2.5%", "97.5%")])
data_frame(site = seq_along(Y),
Y = Y,
Y.mean = Y.mean,
Y.975 = Y.qnt[, 2],
Y.025 = Y.qnt[, 1]) %>>%
ggplot() +
geom_point(aes(x = site, y = Y)) +
geom_line(aes(x = site, y = Y.mean)) +
geom_ribbon(aes(x = site, ymin = Y.025, ymax = Y.975), alpha = 0.3) +
theme_bw() +
theme(
panel.grid = element_blank()
) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 30))
})()
options(repr.plot.width = 8)
- 左: 空間相関あり
- 右: 空間相関なし
library(gridExtra)
grid.arrange(gp.car, gp.glmm, ncol = 2)

11.4 空間統計モデルが作り出す確率場¶
- 相互作用する確率変数でうめつくされた空間は確率場と呼ばれる
- $\{r_i\}$ は マルコフ確率場
隣と似ている度合いが変わると確率場$\{r_i\}$はどう影響されるか
readLines("chap11-model3.jags") %>>% cat(sep = "\n")
data.list3 <- list(
N.site = length(Y),
Y = matrix(c(Y, Y, Y), length(Y), 3),
Tau = c(1000, 20, 0.01)
)
m3 <- jags.model(
file = "chap11-model3.jags",
data = data.list3,
n.chain = 3,
n.adapt = 100
)
post.jags3 <- coda.samples(m3, variable.names = c("r"), n.iter = 200, thin = 1)
# saveRDS(post.jags3, file = "chap11-post-jags3.rds")
post.jags3 <- readRDS("chap11-post-jags3.rds")
summary(post.jags3)
str(post.jags3)
- s = 0.0316
options(repr.plot.width = 4)
post.jags3 %>>% purrr::map_df(function(x){as_data_frame(x)}) %>>% dplyr::sample_n(3) %>>%
select(ends_with("1]")) %>>% t() %>>% as_data_frame() %>>%
purrr::dmap(function(x){exp(x)}) %>>%
mutate(site = seq_along(Y), Y = Y) %>>%
ggplot() +
geom_point(aes(x = site, y = Y)) +
geom_line(aes(x = site, y = V1), colour = gray(0.6)) +
geom_line(aes(x = site, y = V2), colour = gray(0.65)) +
geom_line(aes(x = site, y = V3), colour = gray(0.7)) +
theme_bw() + theme(panel.grid = element_blank()) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 25))

- s = 0.224
post.jags3 %>>% purrr::map_df(function(x){as_data_frame(x)}) %>>% dplyr::sample_n(3) %>>%
select(ends_with("2]")) %>>% t() %>>% as_data_frame() %>>%
purrr::dmap(function(x){exp(x)}) %>>%
mutate(site = seq_along(Y), Y = Y) %>>%
ggplot() +
geom_point(aes(x = site, y = Y)) +
geom_line(aes(x = site, y = V1), colour = gray(0.6)) +
geom_line(aes(x = site, y = V2), colour = gray(0.65)) +
geom_line(aes(x = site, y = V3), colour = gray(0.7)) +
theme_bw() + theme(panel.grid = element_blank()) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 25))

- s = 10.0
post.jags3 %>>% purrr::map_df(function(x){as_data_frame(x)}) %>>% dplyr::sample_n(3) %>>%
select(ends_with("3]")) %>>% t() %>>% as_data_frame() %>>%
purrr::dmap(function(x){exp(x)}) %>>%
mutate(site = seq_along(Y), Y = Y) %>>%
ggplot() +
geom_point(aes(x = site, y = Y)) +
geom_line(aes(x = site, y = V1), colour = gray(0.6)) +
geom_line(aes(x = site, y = V2), colour = gray(0.65)) +
geom_line(aes(x = site, y = V3), colour = gray(0.7)) +
theme_bw() + theme(panel.grid = element_blank()) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
ylim(c(0, 25))

11.5 空間相関モデルと欠測のあるデータ¶
状態空間モデルの場合は,モデルを少し書き換える必要がある (どこが欠測かを明示する必要がある)
空間相関あり
readLines("chap11-model4.jags") %>>% cat(sep = "\n")
data.list4 <- (function(){
Idx.obs <- c(1:50)[-c(6, 9, 12, 13, 26:30)]
Y.obs <- Y[Idx.obs]
list(
N.site = length(Y),
Idx.obs = Idx.obs,
Y.obs = Y.obs,
N.obs = length(Y.obs)
)
})()
m4 <- jags.model(
file = "chap11-model4.jags",
data = data.list4,
n.chain = 3,
n.adapt = 100
)
post.jags4 <- coda.samples(
m4,
c("r", "s"),
n.iter = 10000,
thin = 10
)
# saveRDS(post.jags4, file = "chap11-post-jags4.rds")
post.jags4 <- readRDS("chap11-post-jags4.rds")
summary(post.jags4)
data.list4$Idx.obs
missing.intervals <- purrr::map2(c(6, 9, 12, 13, 26:30) - 0.5,
c(6, 9, 12, 13, 26:30) + 0.5,
function(xmin, xmax){
geom_rect(mapping = aes_(xmin = xmin, xmax = xmax,
ymin = -Inf, ymax = Inf),
fill = gray(0.9, alpha = 0.9))
})
gp.car.na <- (function(){
Y.mean <- exp(summary(post.jags4[, grep("r", varnames(post.jags4))])$statistics[, "Mean"])
Y.med <- exp(summary(post.jags4[, grep("r", varnames(post.jags4))])$quantiles[, c("50%")])
Y.qnt <- exp(summary(post.jags4[, grep("r", varnames(post.jags4))])$quantiles[, c("2.5%", "97.5%")])
p.fill <- rep("black", 50)
p.fill[data.list4$Idx.obs] <- "white"
data_frame(site = seq_along(Y),
Y = Y,
Y.mean = Y.mean,
Y.med = Y.med,
Y.975 = Y.qnt[, 2],
Y.025 = Y.qnt[, 1]) %>>%
ggplot() +
missing.intervals +
geom_point(aes(x = site, y = Y), shape = 21, fill = p.fill) +
geom_line(aes(x = site, y = Y.mean), linetype = "dotted") +
geom_line(aes(x = site, y = Y.med)) +
geom_ribbon(aes(x = site, ymin = Y.025, ymax = Y.975), alpha = 0.3) +
theme_bw() +
theme(
panel.grid = element_blank()
) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
scale_y_continuous(breaks = seq(0, 25, 5), limits = c(0, 30))
})()
空間相関なし
readLines("chap11-model5.jags") %>>% cat(sep="\n")
data.list5 <- (function(){
Y.na <- Y
Y.na[c(6, 9, 12, 13, 26:30)] <- NA
list(
N.site = length(Y),
Y = Y.na
)
})()
data.list5
m5 <- jags.model(
file = "chap11-model5.jags",
data = data.list5,
n.chain = 3,
n.adapt = 100
)
post.jags5 <- coda.samples(
m5,
c("r", "beta", "s"),
n.iter = 10000,
thin = 10
)
# saveRDS(post.jags5, file = "chap11-post-jags5.rds")
post.jags5 <- readRDS("chap11-post-jags5.rds")
gelman.diag(post.jags5)
summary(post.jags5)
gp.glmm.na <- (function(){
beta.mean <- summary(post.jags5[, "beta"])$statistics[["Mean"]]
beta.med <- summary(post.jags5[, "beta"])$quantiles[["50%"]]
Y.mean <- exp(beta.mean + summary(post.jags5[, grep("r", varnames(post.jags5))])$statistics[, "Mean"])
Y.med <- exp(beta.med + summary(post.jags5[, grep("r", varnames(post.jags5))])$quantiles[, c("50%")])
Y.qnt <- exp(beta.med + summary(post.jags5[, grep("r", varnames(post.jags5))])$quantiles[, c("2.5%", "97.5%")])
p.fill <- rep("black", 50)
p.fill[data.list4$Idx.obs] <- "white"
data_frame(site = seq_along(Y),
Y = Y,
Y.mean = Y.mean,
Y.med = Y.med,
Y.975 = Y.qnt[, 2],
Y.025 = Y.qnt[, 1]) %>>%
ggplot() +
missing.intervals +
geom_point(aes(x = site, y = Y), shape = 21, fill = p.fill) +
geom_line(aes(x = site, y = Y.mean), linetype = "dotted") +
geom_line(aes(x = site, y = Y.med)) +
geom_ribbon(aes(x = site, ymin = Y.025, ymax = Y.975), alpha = 0.3) +
theme_bw() +
theme(
panel.grid = element_blank()
) +
xlab(expression("Position "*italic("j"))) +
ylab(expression("Number of individuals "*italic("y")[italic("j")])) +
scale_y_continuous(breaks = seq(0, 25, 5), limits = c(0, 30))
})()
options(repr.plot.width = 8, repr.plot.height = 3)
- 左: 空間相関あり
- 右: 空間相関なし
(点線は事後平均,線は中央値)
grid.arrange(gp.car.na, gp.glmm.na, ncol = 2)

11.6 まとめ¶
- 空間構造のあるデータでは空間相関を考慮した統計モデルを用いる
- 空間相関のある場所差を生成する intristic Gaussian CAR モデルは WinBUGS の
car.normal()で扱える - intristic Gaussian CARモデルは状態空間モデルとしても表現できる
- JAGS で扱う場合にはこちら
- 空間相関のある場所差は確率場を使って表現できる
- 空間相関を考慮した階層ベイズモデルは欠測のあるデータを予測する用途にも使える
devtools::session_info()